Segment Anything(SAM)是Meta推出的图像分割AI模型,能够智能识别并精准分割图片中的任意物体,为图像处理与计算机视觉应用提供强大基础能力。
访问官网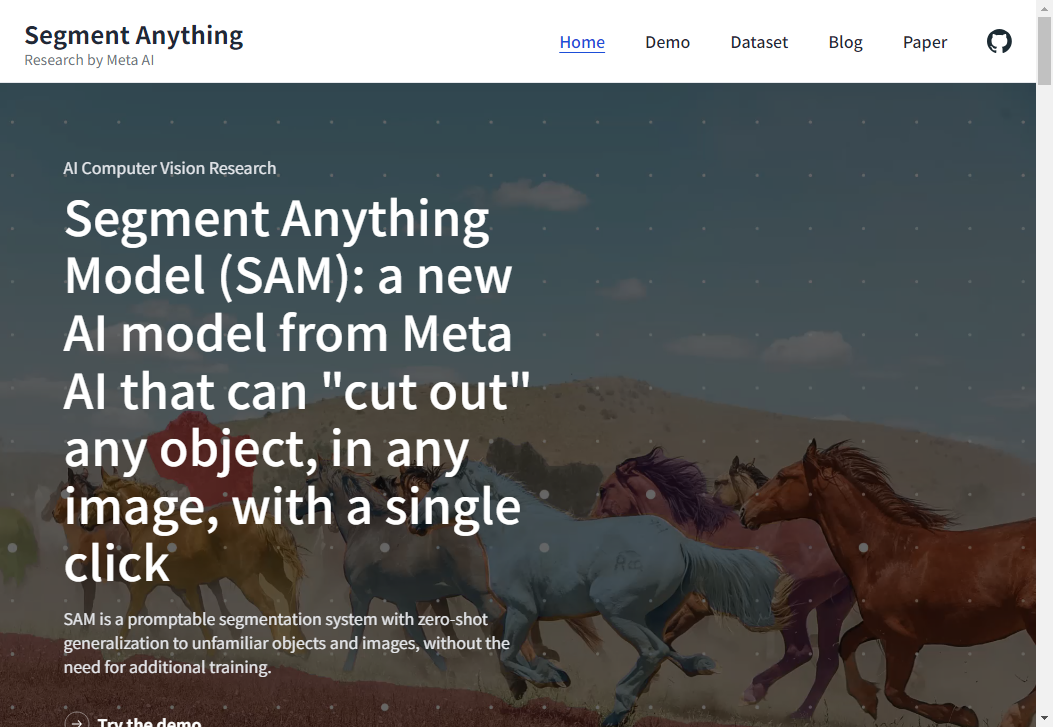
通过点击、画框或输入文字即可精准锁定任意物体,无需预先训练特定类别。用户只需提供简单的提示,模型便能立即生成高质量掩码,大幅降低图像分割的操作门槛。
模型在海量图像上训练后,无需针对新场景进行微调,就能分割出从未见过的物体类别。无论是医疗影像、卫星图片还是日常照片,都能直接获得可靠的分割结果,真正实现一次训练、到处可用。
生成的掩码在物体轮廓处保持锐利且稳定的边界,即使是毛发、树枝等复杂纹理也能细致刻画。专业用户可直接将分割结果用于图像编辑、数据集标注或3D重建,无需二次修正。
Meta AI 在计算机视觉领域持续推进基础模型研究,发布了图像掩码自编码器 MAE 等成果,为后续统一分割框架积累了技术储备。同年,社区对提示驱动通用视觉模型的构想开始形成。
Meta AI 于 4 月正式发布 Segment Anything(SAM)模型及其配套的 SA-1B 数据集。SAM 基于 Transformer 架构,支持点、框、文本等灵活提示,实现零样本图像分割。开源后迅速成为计算机视觉领域里程碑式工具。
2024 年 7 月,Meta 推出 SAM 2,将分割能力从图像扩展到视频,实现实时视频对象分割。同年 10 月发布 SAM 2.1,优化边缘细节与长视频稳定性,并开源 SA-V 数据集。社区涌现大量应用,包括医疗影像、遥感分析等垂直场景。
Segment Anything 生态持续壮大,SAM 2.2 版本引入更高效的稀疏提示策略与跨帧一致性优化。多模态集成成为趋势,与扩散模型、大语言模型协同的图像编辑和生成工具逐步成熟,在工业质检、自动驾驶等领域落地加速。